码到成功
GAN 与 CycleGAN
先热个身:GAN 这件事,说白了就是“真假对练”
原文开头把 CNN、RNN、GAN 放在一起提,其实是很典型的那个时代的深度学习视角。前两个大家都比较熟,而 GAN 最特别的地方在于:
它不是单边学,而是两边互相顶着练。
其中:
G是生成器GeneratorD是判别器Discriminator
D 的任务很直接:
- 真实图片,希望它判成
1 - 生成图片,希望它判成
0
而 G 的任务就有点“使坏”的意思:
- 给它一段随机噪声
- 它想办法生成一张看起来像真的图
- 最终目标是把
D骗过去

你如果把整个过程翻成大白话,其实就一句:
先把 D 练成一个很会辨别真假的裁判,再逼 G 把假图做得越来越像真图,直到裁判都分不清。
这也就是原文里那句意思的核心:
- 正样本过
D拟合到1 - 噪声过
G生成负样本 - 负样本再过
D拟合到0 - 再反过来逼
G生成更像真的东西
所以训练 GAN 时,表面看像是两条线,真正最有戏的,其实是那条“生成器通过判别器拿反馈”的路径。
为什么 GAN 会让人觉得很有想象力
普通卷积网络大多是在做识别:
- 这是什么
- 它在哪
- 它属于哪一类
GAN 不一样,它更像是在做“造东西”。
也就是说,它不是只会判断:
这是猫还是狗
它还想学会:
怎么生成一张像猫或者像狗的图
这个转变很大。因为一旦模型开始学“生成”,很多之前只是识别层面的任务,就会自然延展到:
- 图像合成
- 风格迁移
- 图像到图像翻译
- 数据增强
CycleGAN 正是这个方向里非常有代表性的一个版本。
进入主菜:CycleGAN 到底比普通 GAN 多了什么
原文这里的重心很明确,不是泛泛讲 GAN,而是以 CycleGAN 为例说明:
生成对抗网络可以把风格迁移这件事往前推很多。
如果普通 GAN 的基本单元是:
- 一个
G - 一个
D
那么 CycleGAN 会扩成:
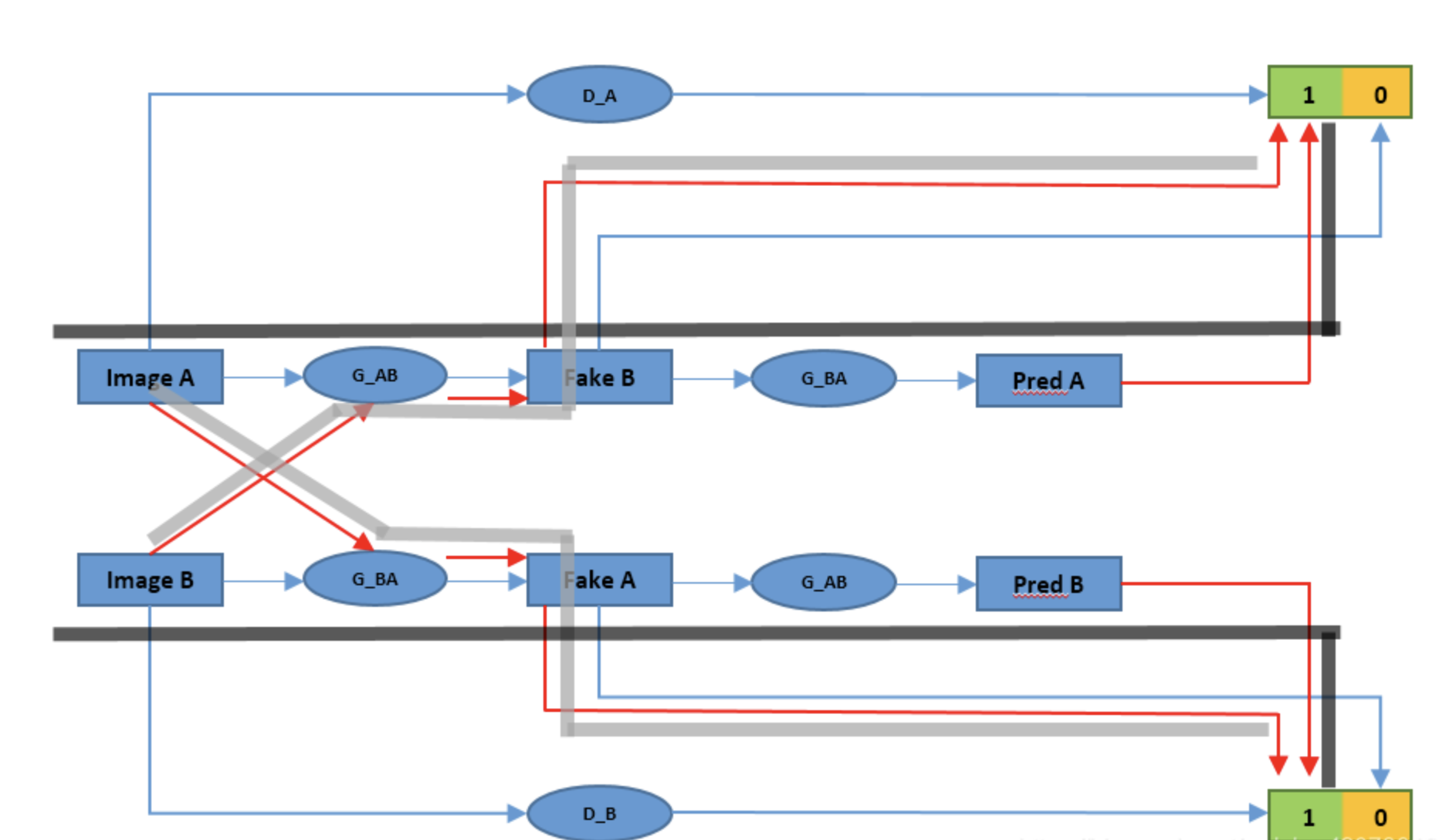
G_AB:把 A 域翻成 B 域G_BA:把 B 域翻成 A 域D_A:判断 A 域真假D_B:判断 B 域真假
也就是说,它不再是“一条单向生成线”,而是形成了两个方向的来回翻译。

这里最值得强调的一点,也是原文特别提醒的点:
图里上下两条看起来像分开的路线,但并不是四套独立网络。
换句话说:
- 上面和下面用到的
G_AB,其实是同一个G_AB G_BA也是同一个G_BA
这点如果不看源码,只看示意图,很容易误会。
为什么它叫 CycleGAN
关键就在那个 Cycle。
它不是只要求:
- A 能翻成 B
- B 能翻成 A
而是要求:
- A 先翻到 B,再翻回 A,别翻丢了
- B 先翻到 A,再翻回 B,也别翻丢了
所以原文里用更直觉的话把训练路线概括成四条:
A → AA → B → AB → BB → A → B
从今天更常见的术语来看,这里面大致对应两类约束:
cycle consistencyidentity / self mapping风格的稳定性约束
但如果你不想记术语,其实抓住一句话就够了:
翻过去可以,翻回来也得说得通。
这个要求一加上,网络就不只是“会模仿另一个域的样子”,而是开始被要求:
迁移时别把原图的关键信息搞没了。
原文为什么会强调双向风格迁移
原文有一句话很抓重点:
CycleGAN 能对风格做双向迁移。
这句话看着平平,实际上是它最亮眼的卖点之一。
比如你有两个域:
- 真实马的照片
- 斑马风格的照片
那 CycleGAN 学到的,不只是:
- 马 → 斑马
还包括:
- 斑马 → 马
而且它希望这两个方向都别太离谱。
这就让 CycleGAN 比很多“只会单边翻译”的结构更自由,也更适合风格迁移这种来回都讲得通的任务。
为什么原文会拿 Pix2Pix 来对照
原文里给出的对比非常直觉:
Pix2Pix更偏单向CycleGAN更偏双向

这个说法虽然是偏工程直觉的总结,但很好懂。
你可以把 Pix2Pix 想成:
给定一个输入条件,朝目标输出方向做翻译。
而 CycleGAN 更像:
不仅能朝一个方向翻,还能朝反方向翻,而且中间要保证闭环。
从论文视角看,Pix2Pix 是典型的 paired image-to-image translation,而 CycleGAN 的代表性标签则是 unpaired image-to-image translation。原文没有把这层术语展开得很学术,但它抓住了更容易让人记住的差别:
一个更像定向翻译,一个更像双向来回翻。
为什么作者会觉得 GAN 还有很大空间
原文后半段有个很鲜明的判断:
CNN 的主干结构已经比较成熟,而 GAN 还有很多没被挖完的空间。
这个判断放在原文语境里,其实很好理解。
因为当时的视觉主干,大体已经走过了:
- 深度优先
- 宽度优先
- 残差连接
这些主路线。
而 GAN 系列还在不断冒出新结构:
- 普通 GAN
- DCGAN
- Pix2Pix
- CycleGAN
- 后面还有越来越多的变体
也就是说,GAN 的想象力更多来自“结构怎么玩”,而不只是“主干再加几层”。
这也是为什么 CycleGAN 会让人觉得眼前一亮。它不是单纯堆参数,而是换了思路:把映射关系做成回环,直接把风格迁移这件事推到一个更灵活的位置上。
用 Python 看一个最小版 GAN 生成器
如果你想更有手感一点,可以先看一个非常小的 PyTorch 生成器例子。它不是完整训练代码,但足够帮助理解 G 在干什么。
import torch
import torch.nn as nn
class TinyGenerator(nn.Module):
def __init__(self, z_dim=100, img_dim=28 * 28):
super().__init__()
self.net = nn.Sequential(
nn.Linear(z_dim, 256),
nn.ReLU(inplace=True),
nn.Linear(256, 512),
nn.ReLU(inplace=True),
nn.Linear(512, img_dim),
nn.Tanh()
)
def forward(self, z):
return self.net(z)
z = torch.randn(8, 100)
G = TinyGenerator()
fake_imgs = G(z)
print(fake_imgs.shape) # [8, 784]
这个小网络做的事很纯粹:
- 输入随机噪声
- 输出一张“假图”的向量表示
至于它像不像真图,就要交给 D 去挑刺了。
用 Python 看一下 CycleGAN 最核心的 cycle loss 直觉
CycleGAN 最关键的不是把图翻过去,而是翻过去以后还能不能回来。
下面这个小例子专门演示 cycle consistency 的味道:
import torch
import torch.nn.functional as F
# real_A -> G_AB(real_A) -> fake_B -> G_BA(fake_B) -> rec_A
real_A = torch.randn(2, 3, 256, 256)
rec_A = torch.randn(2, 3, 256, 256)
cycle_loss_A = F.l1_loss(rec_A, real_A)
print("cycle_loss_A:", cycle_loss_A.item())
这里的意思非常简单:
real_A是原始 A 域图像rec_A是绕一圈回来的结果- 两者越接近越好
这就是为什么 CycleGAN 不只是“变风格”,而是“变完还得能圆回来”。
如果你用 Keras 写 CycleGAN 风格的生成器块
再看一个更贴近图像翻译的最小块:
from tensorflow import keras
from tensorflow.keras import layers
def res_block(x, filters):
shortcut = x
x = layers.Conv2D(filters, 3, padding="same")(x)
x = layers.ReLU()(x)
x = layers.Conv2D(filters, 3, padding="same")(x)
return layers.Add()([shortcut, x])
inputs = keras.Input(shape=(256, 256, 3))
x = layers.Conv2D(64, 7, padding="same")(inputs)
x = layers.ReLU()(x)
x = res_block(x, 64)
model = keras.Model(inputs, x)
model.summary()
这不是完整的 CycleGAN,只是帮你先把“生成器里会有残差块和图像变换路径”这件事摸熟。