码到成功
CrossEntropy-->>交叉熵
- 二分类任务会用到它
- 多分类任务会用到它
- 深度学习里的神经网络分类器也大量使用它
很多人第一次看到交叉熵,会觉得它有点抽象:
- 为什么公式里会有对数?
- 为什么真实标签是
1的位置要重点计算? - 为什么预测越接近真实答案,损失越小?
其实交叉熵并不神秘。
如果把它放回“概率预测是否准确”这个问题里,它的逻辑非常自然。
1. 先用一句话理解交叉熵
可以先记住一句话:
交叉熵用来衡量“模型给真实答案分配了多大概率”。
如果模型对真实类别给出的概率越高,说明预测越靠谱,交叉熵就越小。
如果模型对真实类别给出的概率越低,说明预测越差,交叉熵就越大。
所以从作用上看,交叉熵本质上是在做一件事:
- 奖励高置信度的正确预测
- 惩罚高置信度的错误预测
这就是它特别适合分类问题的原因。
2. 从信息量的角度理解
理解交叉熵,一个很常见的入口是“信息量”。
在信息论里,一个事件发生后带来的信息量可以写成:
I(x) = -log p(x)
这条式子表达的意思并不复杂:
- 如果一个事件本来就很容易发生,也就是概率很高,那么它带来的“意外感”很低,信息量就小
- 如果一个事件本来很不容易发生,也就是概率很低,那么它带来的“意外感”很高,信息量就大
把这个思路放到分类里:
- 如果模型认为真实类别的概率很高,那么“真实结果出现”这件事不意外,损失就应该小
- 如果模型认为真实类别的概率很低,那么“真实结果出现”这件事很意外,损失就应该大
这正是交叉熵的直觉来源。
3. 二分类交叉熵公式
二分类里,真实标签通常记为:
y = 1表示正类y = 0表示负类
模型输出一个概率 p,表示“样本属于正类的概率”。
这时,二分类交叉熵通常写成:
L = -[y log(p) + (1 - y) log(1 - p)]
这是最常见的一条公式。
3.1 为什么这个公式合理
分两种情况看就很清楚。
当 y = 1
公式变成:
L = -log(p)
这说明:
- 如果
p很接近1,那么损失很小 - 如果
p很接近0,那么损失很大
这很符合直觉,因为真实标签就是正类,模型本来就应该把正类概率打高。
当 y = 0
公式变成:
L = -log(1 - p)
这说明:
- 如果
p很接近0,那么损失很小 - 如果
p很接近1,那么损失很大
也符合直觉,因为真实标签是负类,模型就不该给正类很高概率。
3.2 用几个数感受一下
假设真实标签是 y = 1。
如果模型输出:
p = 0.9
那么损失大约是:
-log(0.9) ≈ 0.105
如果模型输出:
p = 0.5
那么损失大约是:
-log(0.5) ≈ 0.693
如果模型输出:
p = 0.1
那么损失大约是:
-log(0.1) ≈ 2.303
可以看到:
- 预测越准,损失越小
- 对真实类别越不自信,损失越大
4. 多分类交叉熵公式
如果是多分类问题,模型通常会输出一个概率分布:
[p1, p2, p3, ..., pn]
其中:
- 每个
pi都表示样本属于第i类的概率 - 所有概率加起来等于
1
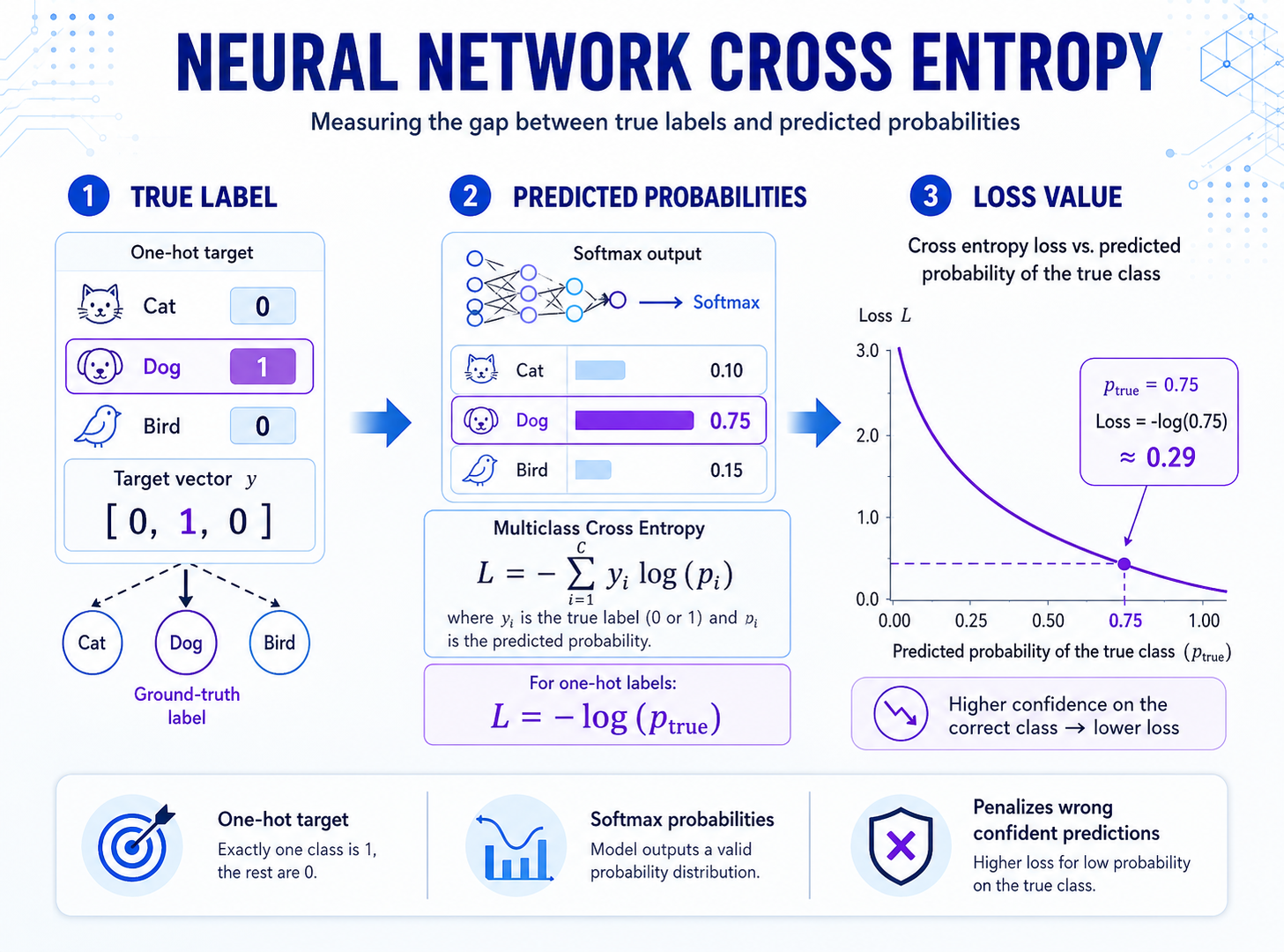
如果真实标签采用 one-hot 形式表示,那么多分类交叉熵可以写成:
L = -Σ yi log(pi)
这里:
yi是真实标签pi是模型预测该类别的概率
4.1 为什么这个公式很简洁
因为 one-hot 标签里只有真实类别对应的位置是 1,其他位置都是 0。
例如三分类任务里,真实标签如果是第 2 类:
y = [0, 1, 0]
模型预测概率如果是:
p = [0.2, 0.7, 0.1]
那么交叉熵就是:
L = -(0*log(0.2) + 1*log(0.7) + 0*log(0.1))
= -log(0.7)
所以多分类交叉熵本质上还是那句话:
- 只重点关心真实类别对应的预测概率
真实类别概率越高,损失越小。
5. 交叉熵和熵、KL 散度是什么关系
很多文章会把交叉熵、熵、KL 散度放在一起讲。
如果你只是做模型训练,其实不用把它们想得太复杂。
可以先用下面这组关系来理解:
- 熵:描述一个分布本身的不确定性
- 交叉熵:描述用一个预测分布去刻画真实分布时的代价
- KL 散度:描述两个分布之间的差异
它们之间有一个常见关系式:
H(P, Q) = H(P) + D_KL(P || Q)
这里:
H(P, Q)是交叉熵H(P)是真实分布的熵D_KL(P || Q)是 KL 散度
如果训练数据中的真实分布 P 已经固定,那么最小化交叉熵,等价于最小化预测分布和真实分布之间的差异。
从训练的角度,这就足够用了。
6. 为什么分类任务常用交叉熵,而不是均方误差
这是一个很常见的问题。
均方误差也能算损失,那为什么分类里大家更常用交叉熵?
主要有几个原因。
6.1 它更符合概率输出的目标
分类模型通常输出的是概率。
交叉熵直接度量“真实类别的概率有没有被打高”,和任务目标更贴近。
6.2 它对错误且自信的预测惩罚更强
如果模型非常自信,但却把类别预测错了,交叉熵会给出很大的惩罚。
这有助于推动模型更快修正方向。
6.3 它和 sigmoid、softmax 搭配非常自然
在二分类里,输出层常配 sigmoid。
在多分类里,输出层常配 softmax。
交叉熵和这两类输出形式配合得非常顺畅。
7. 交叉熵在模型训练里到底做了什么
从训练流程看,可以把它理解成下面几步:
- 模型先输出每个类别的预测概率
- 交叉熵根据真实标签计算损失
- 优化器根据损失反向传播
- 参数更新后,模型会逐步提高真实类别的预测概率
所以交叉熵的作用不是“直接给出分类结果”,而是:
- 为模型提供一个可优化的目标函数
模型训练的核心,就是不断让这个损失变小。
8. 常见应用场景
交叉熵最典型的使用场景就是分类。
8.1 二分类
例如:
- 垃圾邮件识别
- 用户是否流失判断
- 欺诈识别
- 评论正负倾向判断
这类问题通常只需要判断两个类别,常用二分类交叉熵。
8.2 多分类
例如:
- 手写数字识别
- 图片类别识别
- 文本主题分类
- 商品类目预测
这类问题常用多分类交叉熵。
8.3 语义分割
在像素级分类任务中,每个像素点都要预测属于哪一类。
这类任务通常也会大量使用交叉熵,或者在交叉熵基础上做一些变体。
8.4 语言模型训练
语言模型每一步都在做“下一个词元预测”。
本质上,这也是一个多分类问题,所以交叉熵同样非常核心。
9. 一个最简单的直觉例子
假设有一个三分类任务,类别分别是:
- 猫
- 狗
- 鸟
某个样本的真实标签是“狗”。
如果模型输出:
[猫: 0.1, 狗: 0.8, 鸟: 0.1]
那么交叉熵会比较小,因为真实类别“狗”的概率是 0.8。
如果模型输出:
[猫: 0.7, 狗: 0.2, 鸟: 0.1]
那么交叉熵会比较大,因为真实类别“狗”的概率只有 0.2。
所以交叉熵不会只看“猜没猜对”,它还会看:
- 你猜得有多自信
这点非常重要。
因为一个模型即使分类结果相同,概率质量不同,训练效果也会不同。
10. Python 手写一个二分类交叉熵
先用最基础的 Python + NumPy 实现一次。
import numpy as np
def binary_cross_entropy(y_true, y_pred, eps=1e-12):
y_pred = np.clip(y_pred, eps, 1 - eps)
loss = -(y_true * np.log(y_pred) + (1 - y_true) * np.log(1 - y_pred))
return np.mean(loss)
y_true = np.array([1, 0, 1, 1], dtype=np.float32)
y_pred = np.array([0.9, 0.2, 0.8, 0.6], dtype=np.float32)
loss = binary_cross_entropy(y_true, y_pred)
print(loss)
这里有一个关键点:
np.clip用来避免log(0)
因为:
log(0)
是没有定义的,数值上会出问题。
所以实际实现里通常都会做一个很小的截断保护。
11. Python 手写一个多分类交叉熵
下面用 one-hot 标签做一个简单版本。
import numpy as np
def categorical_cross_entropy(y_true, y_pred, eps=1e-12):
y_pred = np.clip(y_pred, eps, 1 - eps)
loss = -np.sum(y_true * np.log(y_pred), axis=1)
return np.mean(loss)
y_true = np.array([
[1, 0, 0],
[0, 1, 0],
[0, 0, 1]
], dtype=np.float32)
y_pred = np.array([
[0.8, 0.1, 0.1],
[0.2, 0.7, 0.1],
[0.1, 0.2, 0.7]
], dtype=np.float32)
loss = categorical_cross_entropy(y_true, y_pred)
print(loss)
如果你已经知道每个样本真实类别的索引,也可以只取真实类别那一列的概率来计算。
12. 用 PyTorch 计算交叉熵
在实际深度学习项目里,更常见的是直接用框架内置实现。
12.1 二分类:BCELoss 或 BCEWithLogitsLoss
import torch
import torch.nn as nn
y_true = torch.tensor([1., 0., 1., 1.])
y_pred = torch.tensor([0.9, 0.2, 0.8, 0.6])
criterion = nn.BCELoss()
loss = criterion(y_pred, y_true)
print(loss.item())
不过更常见、更稳妥的写法是:
import torch
import torch.nn as nn
logits = torch.tensor([2.2, -1.4, 1.6, 0.7])
y_true = torch.tensor([1., 0., 1., 1.])
criterion = nn.BCEWithLogitsLoss()
loss = criterion(logits, y_true)
print(loss.item())
为什么很多人更推荐 BCEWithLogitsLoss?
因为它把:
sigmoid- 二分类交叉熵
合在了一起,数值稳定性通常更好。
12.2 多分类:CrossEntropyLoss
import torch
import torch.nn as nn
logits = torch.tensor([
[2.5, 0.3, 0.2],
[0.1, 1.8, 0.4],
[0.2, 0.5, 2.1]
], dtype=torch.float32)
labels = torch.tensor([0, 1, 2], dtype=torch.long)
criterion = nn.CrossEntropyLoss()
loss = criterion(logits, labels)
print(loss.item())
这里有一个非常重要的点:
CrossEntropyLoss输入的通常是logits- 不是已经做完
softmax的概率
也就是说,很多情况下你不需要自己先写:
softmax(logits)
再传给 CrossEntropyLoss。
直接传原始输出更常见,也更稳定。
13. 交叉熵为什么常和 softmax 一起出现
在多分类任务里,模型最后一层常常会输出一组原始分数,也就是 logits。
这些值本身不是概率。
softmax 的作用是把它们转换成一个概率分布:
pi = exp(zi) / Σ exp(zj)
其中:
zi是第i类的原始分数pi是第i类的预测概率
然后交叉熵会根据真实标签去衡量这个概率分布是否合理。
所以这套组合的逻辑是:
- 模型输出原始分数
softmax把分数转成概率- 交叉熵计算损失
14. 实际使用中的几个注意点
14.1 不要让预测概率直接等于 0 或 1
因为这会带来对数计算问题,也容易导致数值不稳定。
实际实现中通常会做截断,或者直接使用框架封装好的损失函数。
14.2 多分类里要分清“标签索引”和 “one-hot 标签”
不同框架对输入格式要求不同。
例如 PyTorch 的 CrossEntropyLoss 通常要求类别索引,而不是 one-hot 编码。
14.3 类别不平衡时,普通交叉熵可能不够
如果某些类别样本特别少,模型可能更偏向多数类。
这时可以考虑:
- 加权交叉熵
- Focal Loss
- 重采样
14.4 交叉熵小,不代表所有指标都一定最好
训练时交叉熵常常很重要,但评估模型时还需要结合任务本身看:
- 准确率
- 精确率
- 召回率
- F1
- AUC
不同任务关注点可能不同。
15. 一个更实用的训练片段
下面给一个非常简化的 PyTorch 多分类训练示例:
import torch
import torch.nn as nn
import torch.optim as optim
model = nn.Linear(10, 3)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
x = torch.randn(8, 10)
y = torch.tensor([0, 1, 2, 1, 0, 2, 1, 0], dtype=torch.long)
logits = model(x)
loss = criterion(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(loss.item())
这个例子里,交叉熵承担的角色非常清楚:
- 模型给出每个类别的原始分数
- 损失函数根据真实标签评估误差
- 优化器根据误差更新参数